AI & ML Models
0.0 (0 reviews) • 0 downloads
Twitter Expert Non-Expert User Classifier Streamlit in Python Projects
र 1000
Twitter Expert Non-Expert User Classifier Streamlit in Python Projects
Technical Details
Domain : Python
Database : Sqlite
Tools : Anaconda
Run Tools: VS Code
Database : Sqlite
Tools : Anaconda
Run Tools: VS Code
Secure Payment
Instant Download
GST Invoice
24/7 Support
About This Product
Twitter Expert Non-Expert User Classifier Streamlit in Python Projects
Abstract
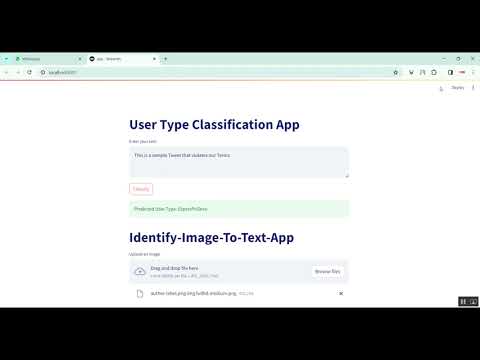
Social media platforms like Twitter host users with varying levels of expertise in specific domains, making it challenging to identify authoritative sources of information. This project focuses on Twitter Expert vs Non-Expert User Classification using Streamlit in Python, which automatically classifies Twitter users as experts or non-experts based on their profiles, tweets, and engagement patterns. The system collects user data such as bio, tweet content, follower count, retweets, hashtags, and mentions through the Twitter API. Natural Language Processing (NLP) techniques are used to extract features from textual content, while machine learning classifiers like Random Forest, Support Vector Machines (SVM), or Gradient Boosting are used for prediction. Streamlit provides an interactive interface for users to input Twitter handles and visualize classification results. The project aims to support knowledge verification, influencer identification, and content credibility assessment on social media platforms.
Existing System
Existing approaches to identifying expert users on Twitter often rely on manual evaluation, keyword matching in bios or tweets, or basic heuristics such as follower count. While partially effective, these methods are subjective, error-prone, and fail to account for the quality of content, engagement patterns, or expertise in specific domains. Traditional systems also lack scalability and cannot process large datasets of users in real-time. Many existing solutions do not provide interactive visualization or actionable insights, making it difficult for researchers, marketers, or analysts to identify authoritative voices accurately.
Proposed System
The proposed system implements a Python-based machine learning framework for expert and non-expert classification, integrated with a Streamlit web application for user-friendly interaction. Data is collected from Twitter using the API, including user profiles, tweets, retweet patterns, follower/following ratios, hashtags, and mentions. Text preprocessing is performed using NLP techniques such as tokenization, lemmatization, and vectorization (TF-IDF or word embeddings). Feature engineering incorporates both textual and engagement-based features to train classifiers like Random Forest, Gradient Boosting, or SVM. The Streamlit interface allows users to input a Twitter handle and view a classification result, along with visualizations of the user’s activity and influence metrics. By combining feature-rich analysis with machine learning and interactive visualization, the system provides an automated, accurate, and scalable solution to distinguish experts from non-experts on Twitter, supporting credibility assessment and knowledge discovery.
Abstract
Social media platforms like Twitter host users with varying levels of expertise in specific domains, making it challenging to identify authoritative sources of information. This project focuses on Twitter Expert vs Non-Expert User Classification using Streamlit in Python, which automatically classifies Twitter users as experts or non-experts based on their profiles, tweets, and engagement patterns. The system collects user data such as bio, tweet content, follower count, retweets, hashtags, and mentions through the Twitter API. Natural Language Processing (NLP) techniques are used to extract features from textual content, while machine learning classifiers like Random Forest, Support Vector Machines (SVM), or Gradient Boosting are used for prediction. Streamlit provides an interactive interface for users to input Twitter handles and visualize classification results. The project aims to support knowledge verification, influencer identification, and content credibility assessment on social media platforms.
Existing System
Existing approaches to identifying expert users on Twitter often rely on manual evaluation, keyword matching in bios or tweets, or basic heuristics such as follower count. While partially effective, these methods are subjective, error-prone, and fail to account for the quality of content, engagement patterns, or expertise in specific domains. Traditional systems also lack scalability and cannot process large datasets of users in real-time. Many existing solutions do not provide interactive visualization or actionable insights, making it difficult for researchers, marketers, or analysts to identify authoritative voices accurately.
Proposed System
The proposed system implements a Python-based machine learning framework for expert and non-expert classification, integrated with a Streamlit web application for user-friendly interaction. Data is collected from Twitter using the API, including user profiles, tweets, retweet patterns, follower/following ratios, hashtags, and mentions. Text preprocessing is performed using NLP techniques such as tokenization, lemmatization, and vectorization (TF-IDF or word embeddings). Feature engineering incorporates both textual and engagement-based features to train classifiers like Random Forest, Gradient Boosting, or SVM. The Streamlit interface allows users to input a Twitter handle and view a classification result, along with visualizations of the user’s activity and influence metrics. By combining feature-rich analysis with machine learning and interactive visualization, the system provides an automated, accurate, and scalable solution to distinguish experts from non-experts on Twitter, supporting credibility assessment and knowledge discovery.
Customer Reviews (0)
No reviews yet. Be the first!
Related Products
⭐ Featured
AI & ML Models
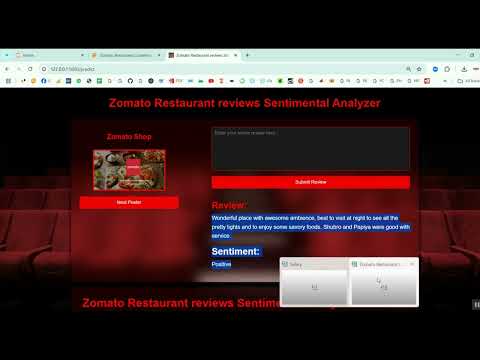
Zomato Restaurant Reviews Sentimental Analyzer in Python Projects
Zomato Restaurant Reviews Sentimental Analyzer in Python Projects
र 1000
⭐ Featured
⭐ Featured
AI & ML Models
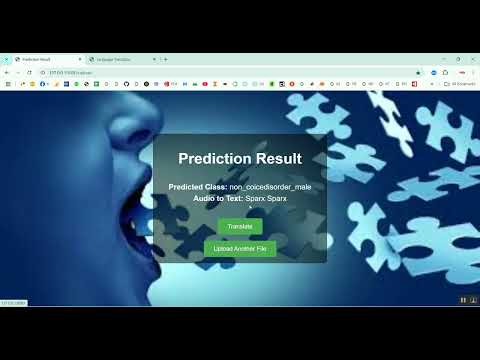
Voice Disorder Prediction using Audio Dataset in Python Projects
Voice Disorder Prediction using Audio Dataset in Python Projects
र 1000
AI & ML Models
Vitamin Deficiency Detection Using Image Processing in Python Projects
Vitamin Deficiency Detection Using Image Processing in Python Projects
र 1000