AI & ML Models
0.0 (0 reviews) • 0 downloads
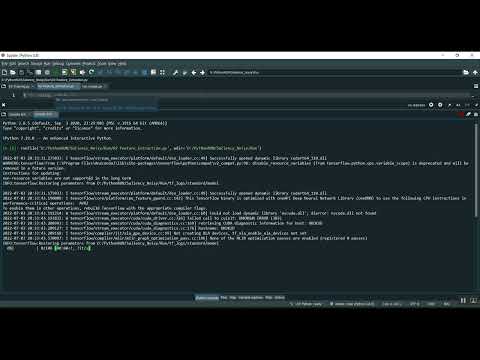
Schizophrenia Data Analysis Jupyter in Python Projects
र 1000
Schizophrenia Data Analysis Jupyter in Python Projects
Technical Details
Domain : Python
Database : Sqlite
Tools : Anaconda
Run Tools: VS Code
Database : Sqlite
Tools : Anaconda
Run Tools: VS Code
Secure Payment
Instant Download
GST Invoice
24/7 Support
About This Product
Schizophrenia Data Analysis Jupyter in Python Projects
Abstract
The Schizophrenia Data Analysis Jupyter Project is a Python-based system designed to analyze clinical, behavioral, and neuroimaging data related to schizophrenia. The project uses machine learning and statistical analysis techniques to identify patterns, risk factors, and potential biomarkers associated with the disorder. Data such as patient demographics, cognitive assessments, EEG signals, and MRI scans are collected and processed to train predictive models. Python libraries like Pandas, NumPy, Scikit-learn, Matplotlib, Seaborn, and TensorFlow/Keras are utilized for data preprocessing, visualization, feature extraction, and model development. This system assists researchers and clinicians in understanding schizophrenia, predicting disease progression, and supporting personalized treatment strategies.
Existing System
Traditional schizophrenia diagnosis and analysis rely on clinical assessments, patient interviews, and observational tests, which are subjective, time-consuming, and prone to inconsistencies. Early automated systems focused mainly on statistical correlations or basic machine learning on small datasets, limiting accuracy and generalization. Existing methods often fail to integrate multimodal data such as neuroimaging and cognitive test results, reducing the ability to detect complex patterns. Moreover, many tools lack interactive platforms for data exploration, visualization, and model evaluation, making research and clinical decision-making less efficient.
Proposed System
The proposed system leverages machine learning and data analysis techniques within a Jupyter Notebook environment to perform comprehensive schizophrenia data analysis. Data preprocessing includes handling missing values, normalization, and encoding categorical variables. Feature extraction identifies relevant biomarkers, cognitive scores, and neuroimaging patterns. Machine learning models such as Random Forest, Support Vector Machine (SVM), and Neural Networks are trained to classify subjects as schizophrenia-affected or healthy controls and to predict disease progression. Python libraries like Pandas and NumPy handle data manipulation, Scikit-learn and TensorFlow/Keras manage model training, and Matplotlib/Seaborn visualize results including accuracy metrics, feature importance, and correlations. This approach improves analytical efficiency, integrates multimodal data, and provides actionable insights to support research and clinical interventions in schizophrenia management.
Abstract
The Schizophrenia Data Analysis Jupyter Project is a Python-based system designed to analyze clinical, behavioral, and neuroimaging data related to schizophrenia. The project uses machine learning and statistical analysis techniques to identify patterns, risk factors, and potential biomarkers associated with the disorder. Data such as patient demographics, cognitive assessments, EEG signals, and MRI scans are collected and processed to train predictive models. Python libraries like Pandas, NumPy, Scikit-learn, Matplotlib, Seaborn, and TensorFlow/Keras are utilized for data preprocessing, visualization, feature extraction, and model development. This system assists researchers and clinicians in understanding schizophrenia, predicting disease progression, and supporting personalized treatment strategies.
Existing System
Traditional schizophrenia diagnosis and analysis rely on clinical assessments, patient interviews, and observational tests, which are subjective, time-consuming, and prone to inconsistencies. Early automated systems focused mainly on statistical correlations or basic machine learning on small datasets, limiting accuracy and generalization. Existing methods often fail to integrate multimodal data such as neuroimaging and cognitive test results, reducing the ability to detect complex patterns. Moreover, many tools lack interactive platforms for data exploration, visualization, and model evaluation, making research and clinical decision-making less efficient.
Proposed System
The proposed system leverages machine learning and data analysis techniques within a Jupyter Notebook environment to perform comprehensive schizophrenia data analysis. Data preprocessing includes handling missing values, normalization, and encoding categorical variables. Feature extraction identifies relevant biomarkers, cognitive scores, and neuroimaging patterns. Machine learning models such as Random Forest, Support Vector Machine (SVM), and Neural Networks are trained to classify subjects as schizophrenia-affected or healthy controls and to predict disease progression. Python libraries like Pandas and NumPy handle data manipulation, Scikit-learn and TensorFlow/Keras manage model training, and Matplotlib/Seaborn visualize results including accuracy metrics, feature importance, and correlations. This approach improves analytical efficiency, integrates multimodal data, and provides actionable insights to support research and clinical interventions in schizophrenia management.
Customer Reviews (0)
No reviews yet. Be the first!
Related Products
⭐ Featured
AI & ML Models
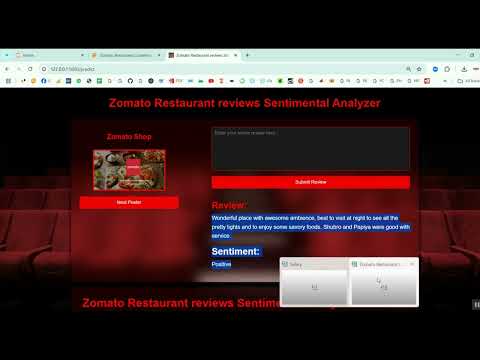
Zomato Restaurant Reviews Sentimental Analyzer in Python Projects
Zomato Restaurant Reviews Sentimental Analyzer in Python Projects
र 1000
⭐ Featured
⭐ Featured
AI & ML Models
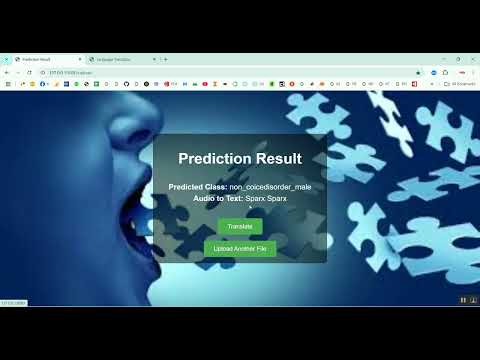
Voice Disorder Prediction using Audio Dataset in Python Projects
Voice Disorder Prediction using Audio Dataset in Python Projects
र 1000
AI & ML Models
Vitamin Deficiency Detection Using Image Processing in Python Projects
Vitamin Deficiency Detection Using Image Processing in Python Projects
र 1000