AI & ML Models
0.0 (0 reviews) • 0 downloads
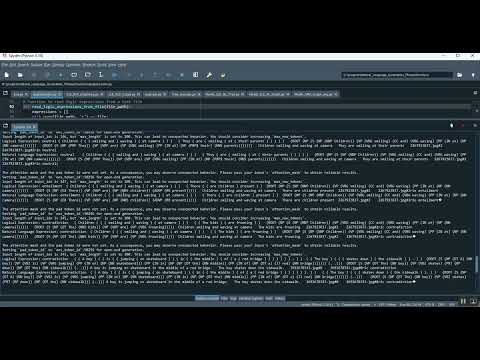
Natural Language Generation Phrase in Python Projects
र 1000
Natural Language Generation Phrase in Python Projects
Technical Details
Domain : Python
Database : Sqlite
Tools : Anaconda
Run Tools: VS Code
Database : Sqlite
Tools : Anaconda
Run Tools: VS Code
Secure Payment
Instant Download
GST Invoice
24/7 Support
About This Product
Natural Language Generation Phrase in Python Projects
Abstract
The Natural Language Generation (NLG) Phrase Project is a Python-based system designed to automatically generate meaningful and contextually relevant phrases or sentences from structured or unstructured data. The project leverages Natural Language Processing (NLP) and machine learning techniques to understand input data, identify patterns, and produce human-like text. Implemented using Python libraries such as NLTK, SpaCy, TensorFlow, Keras, and GPT-based models, the system can be applied to generate automated summaries, chatbot responses, report generation, and content creation. By automating text generation, the project reduces manual effort, improves efficiency, and enables dynamic communication in applications such as virtual assistants, educational tools, and automated documentation systems.
Existing System
Existing text generation systems often rely on template-based or rule-based methods, which limit flexibility and produce repetitive or unnatural language. These systems are unable to generate context-aware responses, adapt to varying input data, or produce diverse sentence structures. Traditional approaches also struggle with maintaining coherence, grammar correctness, and semantic consistency in generated text. As a result, many existing systems fail to meet the expectations of real-world applications like chatbots, automatic reporting tools, and intelligent content generators.
Proposed System
The proposed Natural Language Generation Phrase system introduces an intelligent and data-driven approach for generating coherent and contextually accurate phrases. The system preprocesses input data using NLP techniques such as tokenization, part-of-speech tagging, and named entity recognition to understand context and structure. It then uses machine learning or deep learning models, including RNNs, LSTMs, or transformer-based architectures like GPT, to generate human-like text phrases. The Python-based system can handle both structured datasets (e.g., tables, numerical data) and unstructured text (e.g., paragraphs, articles) to produce meaningful sentences. Libraries such as TensorFlow/Keras manage model training and inference, while SpaCy/NLTK handle text preprocessing. The system can be deployed as a desktop or web application, allowing users to input data and receive dynamically generated phrases or sentences, making it suitable for automated content generation, intelligent chatbots, and AI-assisted writing platforms.
Abstract
The Natural Language Generation (NLG) Phrase Project is a Python-based system designed to automatically generate meaningful and contextually relevant phrases or sentences from structured or unstructured data. The project leverages Natural Language Processing (NLP) and machine learning techniques to understand input data, identify patterns, and produce human-like text. Implemented using Python libraries such as NLTK, SpaCy, TensorFlow, Keras, and GPT-based models, the system can be applied to generate automated summaries, chatbot responses, report generation, and content creation. By automating text generation, the project reduces manual effort, improves efficiency, and enables dynamic communication in applications such as virtual assistants, educational tools, and automated documentation systems.
Existing System
Existing text generation systems often rely on template-based or rule-based methods, which limit flexibility and produce repetitive or unnatural language. These systems are unable to generate context-aware responses, adapt to varying input data, or produce diverse sentence structures. Traditional approaches also struggle with maintaining coherence, grammar correctness, and semantic consistency in generated text. As a result, many existing systems fail to meet the expectations of real-world applications like chatbots, automatic reporting tools, and intelligent content generators.
Proposed System
The proposed Natural Language Generation Phrase system introduces an intelligent and data-driven approach for generating coherent and contextually accurate phrases. The system preprocesses input data using NLP techniques such as tokenization, part-of-speech tagging, and named entity recognition to understand context and structure. It then uses machine learning or deep learning models, including RNNs, LSTMs, or transformer-based architectures like GPT, to generate human-like text phrases. The Python-based system can handle both structured datasets (e.g., tables, numerical data) and unstructured text (e.g., paragraphs, articles) to produce meaningful sentences. Libraries such as TensorFlow/Keras manage model training and inference, while SpaCy/NLTK handle text preprocessing. The system can be deployed as a desktop or web application, allowing users to input data and receive dynamically generated phrases or sentences, making it suitable for automated content generation, intelligent chatbots, and AI-assisted writing platforms.
Customer Reviews (0)
No reviews yet. Be the first!
Related Products
⭐ Featured
AI & ML Models
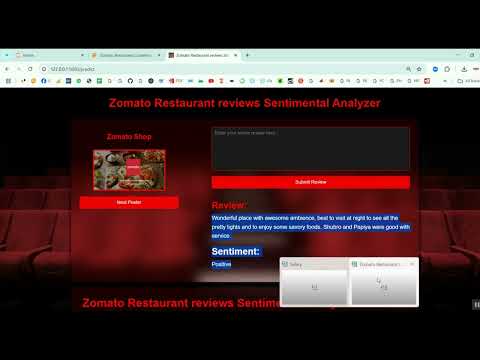
Zomato Restaurant Reviews Sentimental Analyzer in Python Projects
Zomato Restaurant Reviews Sentimental Analyzer in Python Projects
र 1000
⭐ Featured
⭐ Featured
AI & ML Models
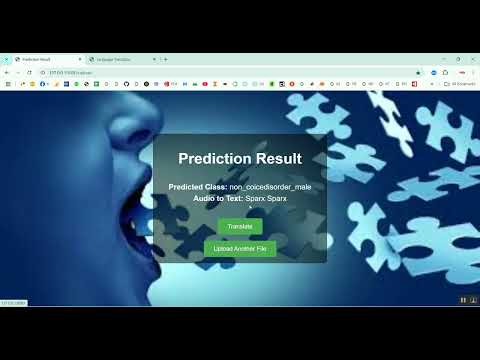
Voice Disorder Prediction using Audio Dataset in Python Projects
Voice Disorder Prediction using Audio Dataset in Python Projects
र 1000
AI & ML Models
Vitamin Deficiency Detection Using Image Processing in Python Projects
Vitamin Deficiency Detection Using Image Processing in Python Projects
र 1000